Perplexity Computer: Agentic AI Redefined
Agentic AI has been over-marketed for more than a year. Most products described as agents have remained structured chat systems with tool calls, short execution windows, and limited state continuity. The user still had to supervise most steps, stitch workflows manually, and recover from fragile handoffs. On February 25 and 26, 2026, Perplexity introduced what it called “Perplexity Computer,” framing it as a unified system that can research, design, code, deploy, and manage end-to-end projects across long-running workflows. If those claims hold under real production load, this launch is not an incremental feature release. It is an attempt to redefine what end users and teams should expect from agentic systems.
The right analysis is not marketing-first and not cynicism-first. The right analysis separates what is established from what is inferred and what remains unknown. Established facts from launch coverage and quoted company statements include multi-model orchestration, isolated compute environments with filesystem and browser access, asynchronous execution, and initial availability for Max subscribers under usage-based pricing. Inferred implications include higher workflow compression for technical and operational tasks, lower context-switch overhead, and stronger appeal for teams that value output throughput over model purity. Unknowns include sustained reliability under multi-hour jobs, real-world safety of connector-heavy execution, and whether users can control cost drift when multiple specialized sub-agents run in parallel.
This piece examines those layers directly. It focuses on architecture, product strategy, business model, and operational constraints. It also explains why Perplexity Computer matters beyond Perplexity. The launch reflects a broader shift from “model as product” to “orchestration system as product,” where value is created by coordinating many models, tools, and environments with persistent memory and outcome-oriented execution.
What Is Actually Announced
Multiple reports on February 25 and 26, 2026 quote Perplexity and CEO Aravind Srinivas describing Computer as a unified AI system that orchestrates files, tools, memory, and models into one working environment. The specific claims repeated across sources include support for 19 models, assignment of specialized roles across subtasks, isolated execution environments, and real browser plus filesystem access. Pricing and availability details in those reports indicate rollout to Max users first, usage-based billing, monthly credits, and later expansion to Pro and enterprise cohorts after load validation.
Those statements matter because they define scope. This is not positioned as a single frontier model with extra plugins. It is presented as a control plane for heterogeneous capabilities. The central claim is orchestration depth rather than model exclusivity. That framing is consistent with a practical reality in 2026: no single model is best at everything. Reasoning quality, coding speed, retrieval behavior, tool execution fidelity, cost per token, latency profile, and multimodal quality still vary substantially across vendors and versions. A product that routes work intentionally across that diversity can deliver better aggregate performance than a single-model stack, if routing quality and failure handling are strong.
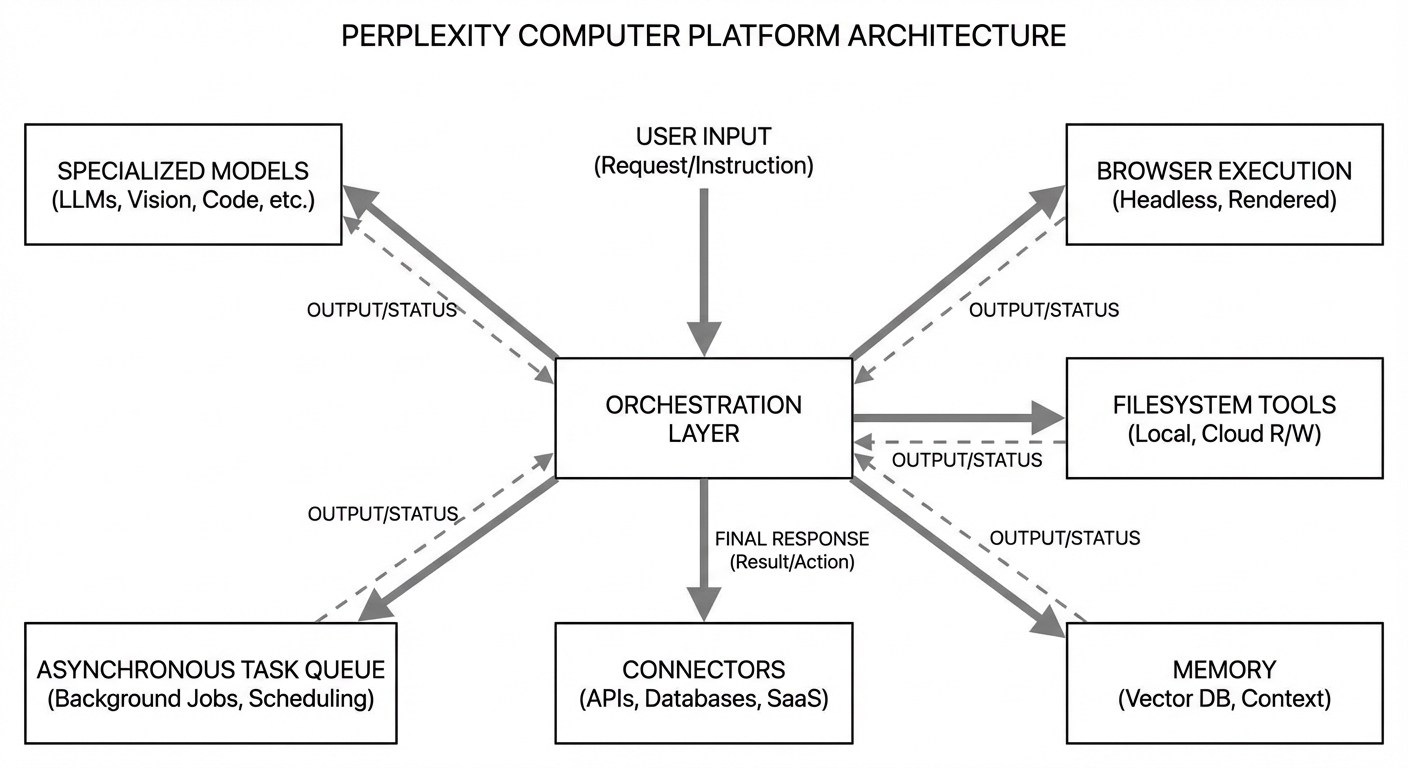
Why This Is a Meaningful Shift in Agent Design
The phrase “agentic AI” has become ambiguous. For technical readers, the useful distinction is between interactive agents and execution agents. Interactive agents respond quickly in a conversational loop and may call tools in short bursts. Execution agents decompose goals, run asynchronous subworkflows, maintain continuity, and return integrated outputs after substantial unattended runtime. Perplexity Computer is explicitly positioned in the second category.
This distinction changes product value. Interactive agents improve local productivity for tasks like drafting, summarizing, and quick analysis. Execution agents target workflow ownership. They can absorb project overhead that currently sits between teams and systems: collecting references, generating intermediate artifacts, writing and running code, validating outputs, and iterating until constraints are met. The key metric is no longer response quality per prompt. It is completed work per unit of human attention.
That is where Perplexity’s framing is strategically sharp. If the product can run “for hours or even months” as quoted in launch coverage, the battleground moves from chatbot preference to orchestration reliability and control economics. The buyer question becomes operational: can this system finish meaningful work without requiring constant rescue.
Architecture: Multi-Model Orchestration as the Core Abstraction
In launch reporting, Srinivas emphasizes that Computer is “multi-model by design,” with model specialization treated like tool specialization. This mirrors how mature software systems treat infrastructure. A production stack does not use one database, one queue, one cache, and one runtime for every workload. It composes components based on workload characteristics. Agent systems are now following the same pattern.
From a systems viewpoint, this architecture has clear upside. First, it allows performance routing. High-complexity reasoning can go to models with stronger chain consistency, while deterministic transformations can go to faster and cheaper models. Second, it supports resilience. If one model has degraded performance, routing can shift without collapsing the whole workflow. Third, it supports cost optimization by assigning high-cost models only where their marginal quality is valuable.
The downside is orchestration complexity. Routing logic itself becomes a failure surface. Model interfaces differ, tool-calling behaviors differ, and failure semantics differ. If a workflow spans multiple agents and one sub-agent fails silently or returns malformed intermediate state, downstream steps may produce confident but invalid outputs. This is why the true quality signal will come from longitudinal workload data, not launch demos.
Isolated Compute Environments: Strong Claim, Hard Requirement
A second notable launch claim is isolated environments with real filesystem and browser access. If implemented with strong isolation boundaries, this addresses a major weakness in first-generation agents: weak execution realism. Many earlier systems could suggest code but could not reliably operate in an environment that resembled real project conditions. Real browser and filesystem access can close that gap.
Yet this also raises the security bar. Agent environments with broad connectors and execution permissions need rigorous controls around credential scope, outbound actions, data retention, audit trails, and rollback. Without robust policy layers, a capable agent can also be an efficient failure amplifier. Enterprises will evaluate this through governance controls, not only task completion rates.
This is where Perplexity’s enterprise trajectory matters. Comet enterprise materials emphasize secure deployment and organizational controls in browser contexts. If Computer inherits and extends those control primitives into agent workflows, the enterprise case strengthens. If controls are shallow relative to autonomy depth, adoption will be limited to low-risk and experimental workloads.
Business Model: Usage-Based Pricing Is Rational, but User Risk Moves Upstream
Perplexity’s launch framing around usage-based pricing is economically coherent for orchestration products. Multi-agent runs consume variable resources depending on task complexity, model selection, and runtime duration. A flat fee can hide cost until margins collapse, or enforce strict caps that cripple usefulness. Usage pricing aligns spend with work volume.
The practical issue is budget predictability. For end users and teams, orchestration depth can convert into cost volatility if tasks spawn many sub-agents or rerun loops after partial failures. Credit systems and spending caps help, but they are not enough by themselves. Serious users will need workload-level observability: per-run token cost, model mix, connector call volume, failure retries, and final output utility. Without this transparency, users cannot optimize behavior and procurement cannot govern spend effectively.
This is a structural trend across agent products in 2026. Capability marketing focuses on what agents can do. Operational adoption depends on whether teams can forecast and control what agents cost.
How Perplexity Computer Compares to the Current Agent Field
A direct benchmark is difficult because vendors publish uneven metrics and define “agent” differently. Still, the market can be segmented in a useful way. There are browser-embedded assistants, coding agents tied to repositories and CI, workflow automation platforms connected to SaaS ecosystems, and general-purpose orchestration systems that attempt to span all of the above. Perplexity Computer is targeting the fourth category.
The closest strategic comparison is not a single model release. It is any system that combines model routing, memory continuity, execution environments, and connectors into a goal-driven control plane. In this segment, differentiation will be decided by five factors: task decomposition quality, long-run reliability, security controls, cost governance, and integration breadth. Model quality still matters, but orchestration quality determines whether capability translates into delivered work.
Perplexity enters this race with two advantages. It already has strong user familiarity around research workflows and citation-oriented answer patterns. It also has clear product momentum around distribution layers such as Comet. The risk is that broad orchestration products can become operationally heavy quickly. They must maintain quality across many domains, not one narrow domain where optimization is easier.
Where the Launch Is Strong
The strongest element is architectural honesty. The company does not pretend one model solves all tasks. It acknowledges specialization and builds around orchestration. This is aligned with how advanced users already work manually, switching tools and models depending on the job. If the platform makes that switching automatic while preserving control, it solves a real friction point.
The second strong element is asynchronous orientation. Most productivity gain from agents will come from reducing synchronous supervision. A system that can run substantial work while a user is offline has materially different economic value than a system that requires constant prompting.
The third strong element is environment realism. Real browser and filesystem access support full-workflow execution rather than synthetic demos. If reliability holds, this can shift agent use from experimentation to production operations.
Where the Launch Is Exposed
The first exposure is reliability at duration. The longer a workflow runs, the more failure points accumulate. State drift, stale assumptions, connector timeouts, partial writes, and tool nondeterminism compound over time. Launch narratives emphasize multi-hour and multi-day execution, which increases scrutiny on durability metrics that are usually not visible in marketing materials.
The second exposure is safety and governance. Execution agents with broad permissions can create real-world side effects. This demands strict permissioning, explicit confirmation boundaries for sensitive actions, forensic logs, and policy constraints that are understandable by non-specialist operators.
The third exposure is user trust under cost uncertainty. Multi-model orchestration can produce excellent outcomes and unexpected bills at the same time. If users cannot predict spend by workload class, adoption will plateau outside high-value use cases.
Evaluation Framework for Teams Adopting Computer
Teams evaluating Perplexity Computer should avoid binary judgments based on launch hype or skepticism. The correct approach is controlled workload testing. Start with three workload classes: bounded research tasks, deterministic build tasks, and mixed tasks with external connectors. Measure completion rate, correction burden, runtime variance, and total cost per completed outcome. Track failure modes in a structured taxonomy: decomposition errors, tool invocation errors, state propagation errors, and policy boundary violations.
Adoption should be phased by risk. Early deployment belongs in reversible workflows with low external side effects. High-impact actions such as production infrastructure changes, billing operations, or legal-communication outputs should stay behind stricter human checkpoints until reliability and governance data are mature.
From a procurement perspective, contract and platform discussions should include explicit controls: max spend per run, configurable model allowlists, retention and deletion controls, exportable logs, and environment-level isolation guarantees. This is not optional detail. It determines whether autonomous execution is governable at scale.
What This Means for the Next Phase of Agentic AI
Perplexity Computer reflects a market transition that now appears durable. The center of gravity is moving from assistant UX to execution systems. Competition is moving from “which model answers better” toward “which orchestration layer completes more work safely at predictable cost.” This favors product organizations that can combine model abstraction, systems engineering, and enterprise control surfaces in one coherent platform.
For users, this transition changes skill requirements. Prompt crafting remains useful, but orchestration literacy becomes more valuable: defining good outcomes, setting constraints, structuring evaluation loops, and diagnosing workflow failures. The operator of the next generation of agentic systems is less a prompt author and more a workflow architect.
For incumbents, the implication is direct. If orchestration becomes the primary product, model providers without strong control planes risk commoditization at the interface layer. For orchestration-first companies, the risk runs the other direction: if underlying model providers vertically integrate and close capability gaps, orchestration margins can compress. This strategic tension will define the next 12 to 24 months.
Twelve-Month Outlook: Realistic Scenarios
Base case: Computer becomes a high-leverage tool for technical users and power operators on specific workflow classes, with measured expansion to Pro and enterprise after reliability tuning. Adoption grows where asynchronous execution and multi-model routing provide obvious ROI.
Upside case: Perplexity demonstrates strong reliability at long runtime, introduces enterprise-grade governance controls quickly, and becomes a default orchestration layer for cross-domain knowledge work. In this case, the product redefines expectations for what “agentic” should mean in commercial software.
Downside case: Reliability variance, opaque cost behavior, or security-control gaps limit trust for mission-critical workflows. Product remains impressive for demos and selective use, but does not cross into broad operational dependency.
Current evidence supports base-case optimism with significant unresolved operational questions. That is a strong launch position, but not a solved execution story.
Key Takeaways
- Perplexity Computer is positioned as an orchestration system, not a single-model assistant.
- Launch claims emphasize 19-model routing, isolated execution environments, real browser and filesystem access, and asynchronous long-running workflows.
- The strategic shift is from response quality per prompt to completed outcomes per unit of human attention.
- Main strengths are architectural realism, asynchronous execution model, and multi-model flexibility.
- Main risks are long-run reliability, governance depth, and spend predictability under usage-based pricing.
- The next phase of agentic competition will be decided by orchestration quality, control surfaces, and cost governance rather than model branding alone.
Sources
- Business Today (Feb 26, 2026): Perplexity Computer launch details and quoted statements
- Semafor (Feb 25, 2026): Perplexity launches Computer super agent
- Benzinga (Feb 25, 2026): Unified platform and pricing rollout details
- The Verge: Perplexity Comet browser launch context
- Perplexity Help Center: Comet for Enterprise context
- Economic Times (Feb 26, 2026): Multi-model and usage model reporting
Keywords
Perplexity, Computer, agentic, AI, orchestration, models, workflow, automation, browser, enterprise, pricing, reliability
Stay Connected
Follow us on @leolexicon on X
Join our TikTok community: @lexiconlabs
Watch on YouTube: @LexiconLabs
Learn More About Lexicon Labs and sign up for the Lexicon Labs Newsletter to receive updates on book releases, promotions, and giveaways.


.jpg)


